

Supporting SIPHER’S Evidence Synthesis
Published: 28 February 2025
Detailing the tools used to provide relevant evidence for SIPHER’s mapping, modelling and evaluation work.
SIPHER’s Evidence Synthesis workstrand brings together information, particularly findings from completed research studies, so that we can explore and understand what we already know about the policy areas in which SIPHER is seeking system change. In January 2025, I gave a presentation at our Research Meeting about the tools I have used as an Information Specialist for the Evidence Synthesis workstrand.
Our workstrand team is an integral part of the consortium and across the years, we have received and responded to many formal and informal evidence requests. Our interactions with colleagues have been collaborative, and the topics have varied considerably, covering income, housing, mental health, nutrition, employment, child poverty and health inequalities. Requests do not always require fully exhaustive searches for all the available evidence, but timescales can be limited, and search short-cuts are often applied.
In this blog, I describe how tools have played an increasingly important part in our work. These can be broadly grouped into three categories i) semi-automation tools ii) rapid reviewing tools iii) and meta-science tools.
Semi-automation of evidence and gap map
The primary product of our workstrand is the Employment and Health Evidence and Gap Map (EGM). The strength of EGMs lies in their ability to simplify complex and diverse research findings in a visual and interactive way. They are helpful in navigating and locating relevant evidence, as well as highlighting research gaps. Allowing multiple questions to be explored, they can provide a fresh perspective on important topics. This Employment and Health review was managed using EPPI-Reviewer to help researchers collaborate, conduct, and manage each step of the review efficiently. Soon after the map publication, we sought to carry out a methodology study to semi-automate, modify and update the review process by developing a binary classifier to support the screening of update searches (See Figure 1). This was carried out in collaboration with the software developers (EPPI-Center at UCL).
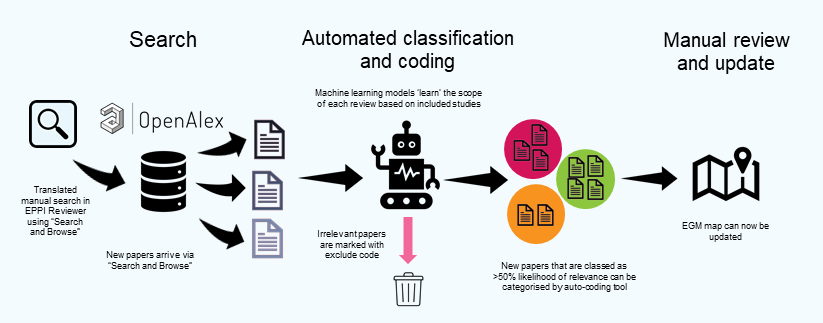
Figure 1: Review workflow. Adapted from Ghouze Z. & Dehdarirad H. (2025) Automation. EPPI Centre, University College London (2025). Adapted with Permission.
Developing the custom classifier required familiarisation of the software. The retrieval, identification and coding of studies were expanded through the exploration of a suite of software features, such as its direct connection with OpenAlex a comprehensive open database that connects the world's research outputs, providing a single data source for studies. We used the software’s “search and browse” facility to bypass manual collection and duplicate checking of records from multiple searches across various databases. Developing an accurate model for classifying new references (as likely relevance) was not simple, because of the broad topic area and inclusion criteria, the heterogeneity of included reviews, and the existing training data being quite small. We did refine the classifier as more items were manually screened, and checked the performance (the accuracy of its classification of items as relevant or not) of the model against three new searches (totalling 1.7K records since 2021) that have been manually screened. The classifier can now support the review process in determining the likely relevance of studies within a search and identifying the cut-off point for manual screening and selection.
We are now undertaking tests to automatically assign codes (ten exposure categories by four outcome categories) to potentially relevant studies using their full texts. We have already successfully categorised items (using EPPI Reviewer’s LLM-based auto-coding tool to process references’ titles and abstracts) according to their study type, as per the colour-coding / segmentation of the original version of the map. Auto-coding also has the potential to support screening and study identification of search results.
We do not envisage a fully automated update of the EGM to a living map given the methodological challenges, only that the process would be more efficient i) to replace the multiple databases searching with the use of a single data source ii) to reduce the numbers of records required to screen through use of a classifier and auto-coding. Given the exploratory nature of this work, our key learning from this experience, is that the decision for an EGM to become living should be planned from the outset of the review so that the potential challenges and steps in the evaluation process are mapped. Considerations may include the EGM structure and the suitability of column and row descriptions for auto-coding.
Rapid reviewing
One challenge that we often faced is the need for a rapid response to the evidence request. Timescales are often constrained, in a majority of cases searching for evidence involves the use of short-cuts (e.g. single source searching), limits (e.g date and language), filters (e.g. study design filters) and selected field searching. Other strategies include combining multiple search facets so that the numbers retrieved are more manageable.
More recently, two artificial intelligent (AI) tools have the potential to support the rapid data-extraction and synthesis of studies at the full-text stage.
- Elicit is a subscription-based tool which allows the rapid data extraction of key data from studies (multiple variables). Elicit supported the identification of themes within a collection of papers on the wider determinants of mental health.
- Notebook LM is a free tool which could generate summaries to studies as well as enable readers to interrogate the study content through the Q and A function This tool was to help understand complex concepts in papers.
Meta-science
This category of tools relates to citations for a collection of research items in a research field, or outputs generated for research mapping or evaluation. A citation is when one document correctly mentions another document. Two notable sources for non-traditional citation information are Altmetrics for citation data from news, X (formely known as Twitter), blogs, Wikipedia, Mendeley and others and Overton for citations from policy documents only which provide quantitative counts of citations to research. Without manually reviewing each citation these tools provide little information about the context of citations. However, Scite is an AI tool that extracts and analyses the citations in other articles as either supporting, contrasting, or just mentioning. These three tools have been used to find external users of the EGM, support evaluation through the generation of summaries of metrics for a collection of SIPHER’s research outputs, and provide early indicators of the impact of research. For non-traditional source citations, there are no tools that can give information on the context of the citations.
Conclusions
These tools are not static and are subject to improvements and change without the users being aware. New tools will also continue to be released. As ever, we face challenges of time, resources, and the need to identify, access and synthesise evidence in a timely way. AI tools can help circumvent these issues and thus change our methodological processes and workflows, but there are potential risks that generative AI can introduce errors, the methods are not transparent and the reviewer does not familiarise themselves with the data in a way that supports the interpretation of the findings.
Currently, AI is a supportive tool, which can reduce the need for duplicate screening and data extraction, with the tool acting as a ‘second reviewer’. With that in mind, we shall report and publish the tool evaluation and changed workflow for the EGM update to help encourage uptake and adoption of automation tools for formal evidence reviews in the future.
I would like to acknowledge the SIPHER Evidence Synthesis Workstrand Team: Dr Fiona Campbell (Lead), Zak Ghouze, and Dr Linda Long.
The views and opinions expressed in this blog are those of the author/authors.
Links and further reading:
Campbell, Fiona; Llewellyn, Jennifer; Chambers, Duncan; Wong, Ruth; Meier, Petra (2025). Employment and Health Evidence & Gap Map. The University of Sheffield. Dataset. https://doi.org/10.15131/shef.data.27619617.v1
- Altmetric. (2025). Altmetric: Discover the attention your research has received. Retrieved from https://www.altmetric.com
- Google Inc. (2025). NotebookLM: Your AI Research Assistant. Retrieved from https://notebooklm.google/
- Ought Inc. (2025). Elicit: The AI Research Assistant. Retrieved from https://elicit.org
- Priem, J., Piwowar, H., & Orr, R. (2022). OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. OpenAlex. Retrieved from https://openalex.org
- Scite Inc. (2025). Scite. Retrieved from https://scite.ai/
Thomas, J. Graziosi, S. Brunton, J. Ghouze, Z. O'Driscoll, P. & Bond, M. & Koryakina, A. (2023) EPPI-Reviewer: advanced software for systematic reviews, maps and evidence synthesis. EPPI Centre, UCL Social Research Institute, University College London.
First published: 28 February 2025
<< Blog

By Dr Ruth Wong, SIPHER Information Specialist
Evidence Synthesis Workstrand 2
University of Sheffield